Overview
Github | Demo | Poster | Report
For background, Atari Breakout was an arcade video game that was created by Steve Wozniak, Nolan Bushnell, and Steve Stristow back in 1976.
This project was built in part with the capstone course during my time at Oregon State’s Comp Sci Program. I was fortunate to work with Ceci Fang, I-Chun Hurng, and Jacob Silverberg on this project as well.
The goal of the project was to redevelop Breakout with Unity and train an intelligent agent to compete against.
Project Plan
From the start, the team decided to break into groups with one group focusing on the development of the game logic while the other group researched how to train machine learning agents with Python and Unity. This allowed the game development team to have roughly a two-week head start, allowing the ML Agent team to research how to structure the learning environment. Our initial plan was fairly aggressive for an eight-week course, yet in hindsight, the development pace allowed for a lot of time towards the end to refine the project and refine the training environment.
Game Structure
For a brief Unity game engine crash course - within specific scenes, assets are defined, then the physics and interactions of those assets are managed by attached C# scripts. Ceci and Jake did a fantastic job at designing the overall game structure design along with the interactions between the paddle, ball, and brick objects. This logic included the gameManager script, which defined the instantiation of the game objects. This also allowed for the creation and management of different game states, such as loading a level or populating the menu objects for a player to select. As shown below, the results allowed for a fairly simplistic use of game objects where the only required objects at the start of the game are the walls; everything else is a spawned object of a class or prefab.
Reinforcement Learning
The main goal of the project was to serve as an introduction to Reinforcement Learning, which is an area of machine learning that is concerned with how intelligent agents take actions in a controlled environment to maximize their reward function.
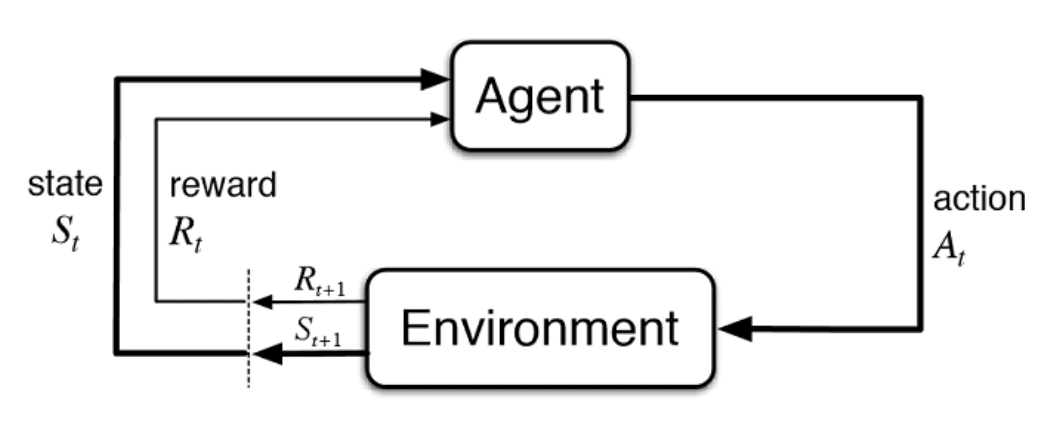
To develop the learning agents for a human player to compete against, we utilized the ML-Agents Unity package. This package is an open-source project that enables games to serve as training environments for intelligent agents. The agent training is performed through Python APIs and begins with defining a Unity game object and appending on Behavior Parameters and Decision Requester components. For example, through the PlayerAgent script, we can define the following interactions:
OnEpisodeBegin()- The method that defines what the agent will do before learning starts and resets the surrounding learning environmentOnActionReceived()- This collects actions that the agent can perform or possible instructions that can be provided to the agent to complete its specific goal. In our instance, we limit the agent to three possible actions - move left, move right, or stay at the current location.CollectObservations()- This important method specifies what metrics the agent will observe and begin to learn from. The team played with several combinations of observations such as the distance from the agent (i.e. the paddle) to the ball, the current position of the agent, along with the location and velocity of the ball.
We can then define the reward and penalty structure once the agent was correctly observing its local environment. To provide a positive reward, we can call the AddReward() along with passing some scalar amount of reward to encourage the agent. The team tried several reward system structures, trying simplistic single rewards for every brick destroyed, rewarding the agent just for keeping the ball alive, along with the non-linear reward function illustrated below. One key thing we discovered was that the general reward function for the agent is dependent on the training environment and training parameters used. For example, a simplistic single reward for a broken brick is a foolproof reward structure, as the agent likely will not get confused or sidetracked by unneeded actions. Yet, if that simple model takes 10-15 hours of training on a medium-duty machine, we might and did opt for a faster reward function to quickly reward the agent for more correct actions. Ultimately, the performance of the trained agent should be evaluated against a test suite or real-world scenarios. While none of the team claims to be a professional at Breakout, any flaws in an ill-trained model were fairly quickly seen.
public void BrickDestroyed()
{
AddReward(1.0f);
bricks_destroyed++;
if ((bricks_destroyed / bricks_available) > 0.1f)
{
AddReward(10f);
}
else if ((bricks_destroyed / bricks_available) > 0.25)
{
AddReward(25f);
}
else if ((bricks_destroyed / bricks_available) > 0.50)
{
AddReward(50f);
}
else if ((bricks_destroyed / bricks_available) > 0.90)
{
AddReward(100f);
}
else if ((bricks_destroyed / bricks_available) > 0.99)
{
AddReward(1000f);
EndEpisode();
}
}
The actual training and model development process to define a reinforcement learning algorithm and policy is fairly abstracted from knowing the details of machine learning, all things considered. The ML-Agents package utilizes PyTorch as the machine learning package and automatically performs multiple training episodes based on the defined number of steps in a configuration file. For details, the Python training model opens a port of the local machine the same port the Unity engine listens to, ultimately passing the observation and action vectors back and forth.
{{< youtube id=“8szEyjQc3zI” >}}
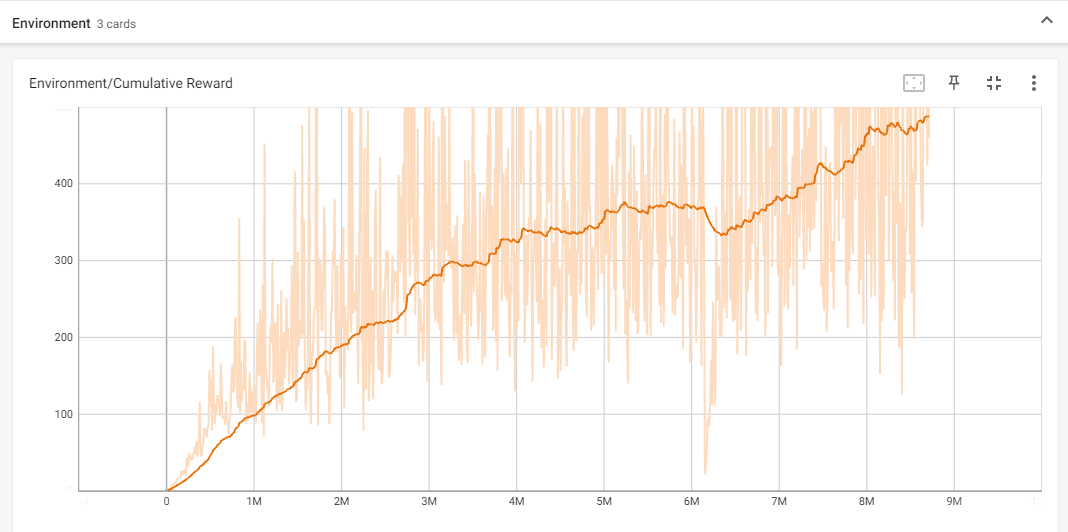
To compare or view two agent brains and the subsequent performance of each, one can view the learning policy results through TensorBoard to compare the policy loss, entropy, and cumulative reward. Stored brain files (stored as .onnx files) can be used once trained by attaching them to the agent component in Unity, then the actions will of the agent be determined by the policy the agent learned in training. One point of improvement the team could have made to the project is testing and optimizing the learning configuration file settings to better support learning efficiency and increase agent performance. As explained, adjusting the rate of learning and tuning of hyperparameters can significantly alter the agent’s training performance. View below for an example of our best-performing agent illustrating a very consistent cumulative reward over time.
Alternatively, we tried to increase learning efficiency through the parallelization of the training environment. This required making numerous duplicates of each learning environment resulting in multiple agents performing and learning at once, all accumulating to a combined policy.
{{< youtube id=“fCwQFpH9X78” >}}
This interestingly led to mixed results. We eventually determined that some bugs within the game, such as the ball flying outside of the game space or the agent holding onto the ball prohibited successfully using the parallel training. This is still a piece of the project that I want to get working correctly because it would cut down on training time significantly.
Learning Outcomes
This project was challenging to complete within the short eight-week term mainly because of the amount of breadth that had to be covered. Unity and game development are challenging to understand given ample time to learn, and both took a significant amount of time to grasp to a level to be efficient enough to develop a game. Some of the tooling and systems used for game development are interesting as well. For example, version controlling a Unity scene is incredibly complex and they push you to use Plastic SCM. We had to utilize Github based on project requirements, which resulted in so many merge conflicts to count, which was frustrating. Nonetheless, I enjoyed working on the machine learning process especially iterating the reward system and searching for the best reward/training split to get the best agent. The team worked incredibly well together too, which always helps. Fun project, but I’m not sure how much game development I’m going to undertake in the future.